
Independent Research in Intelligent Systems
GTech conducts applied research in AI architectures, intelligent automation, and resilient software systems with a focus on structured validation and real-world deployment.
Research Areas
At GTech Research Institute, research is part of our engineering.
Our work is guided by a simple principle:
Intelligent systems must be rigorously designed, validated, and deployable.
We focus on building research that transitions beyond theoretical models and into structured, testable, and maintainable software architectures.
-
Designing structured generative AI systems that integrate tool use, retrieval mechanisms, and controlled reasoning pipelines.
Focus areas:
Agentic LLM workflows
Retrieval-Augmented Generation (RAG) systems
Evaluation and validation frameworks
AI safety and transparency controls
-
Research into systems that integrate multiple data sources and sensor modalities for predictive and adaptive intelligence.
Focus areas:
Multimodal data fusion
Environment-aware system modeling
Intelligent perception pipelines
Structured prediction frameworks
-
Designing software architectures that embed intelligent reasoning into operational workflows.
Focus areas:
Automation pipelines
AI-assisted documentation systems
Data-driven decision frameworks
Scalable backend infrastructure
-
Ensuring research prototypes are built with production pathways in mind.
Focus areas:
Modular system architecture
Controlled access frameworks
Scalable hosting models
Validation and benchmarking
Our Research Areas
-
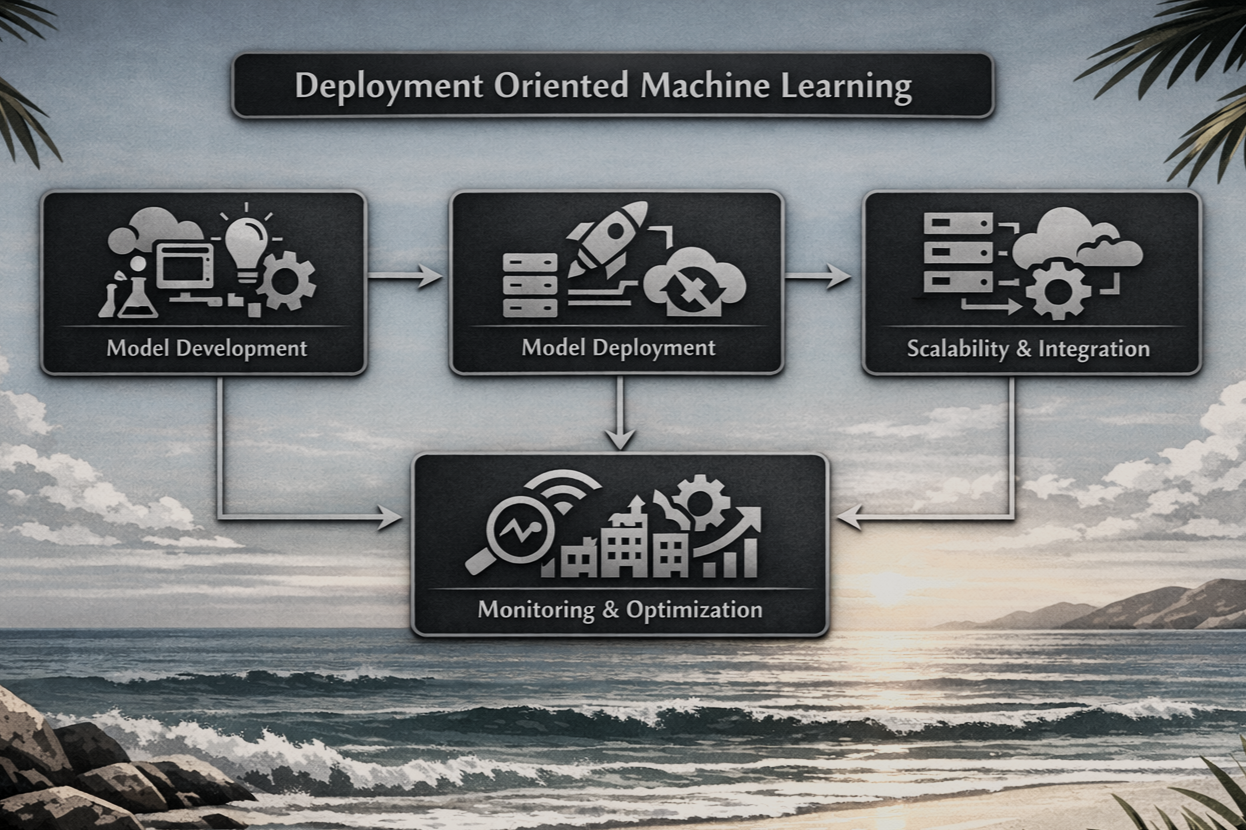
![Deployment-oriented machine learning diagram showcasing flow of applying ML techniques to real-world applications and the fine-tuning loop.]()
Deployment-Oriented Machine Learning
Building end-to-end pipelines that transition machine learning models from experimental setups into real-world, scalable systems.
-
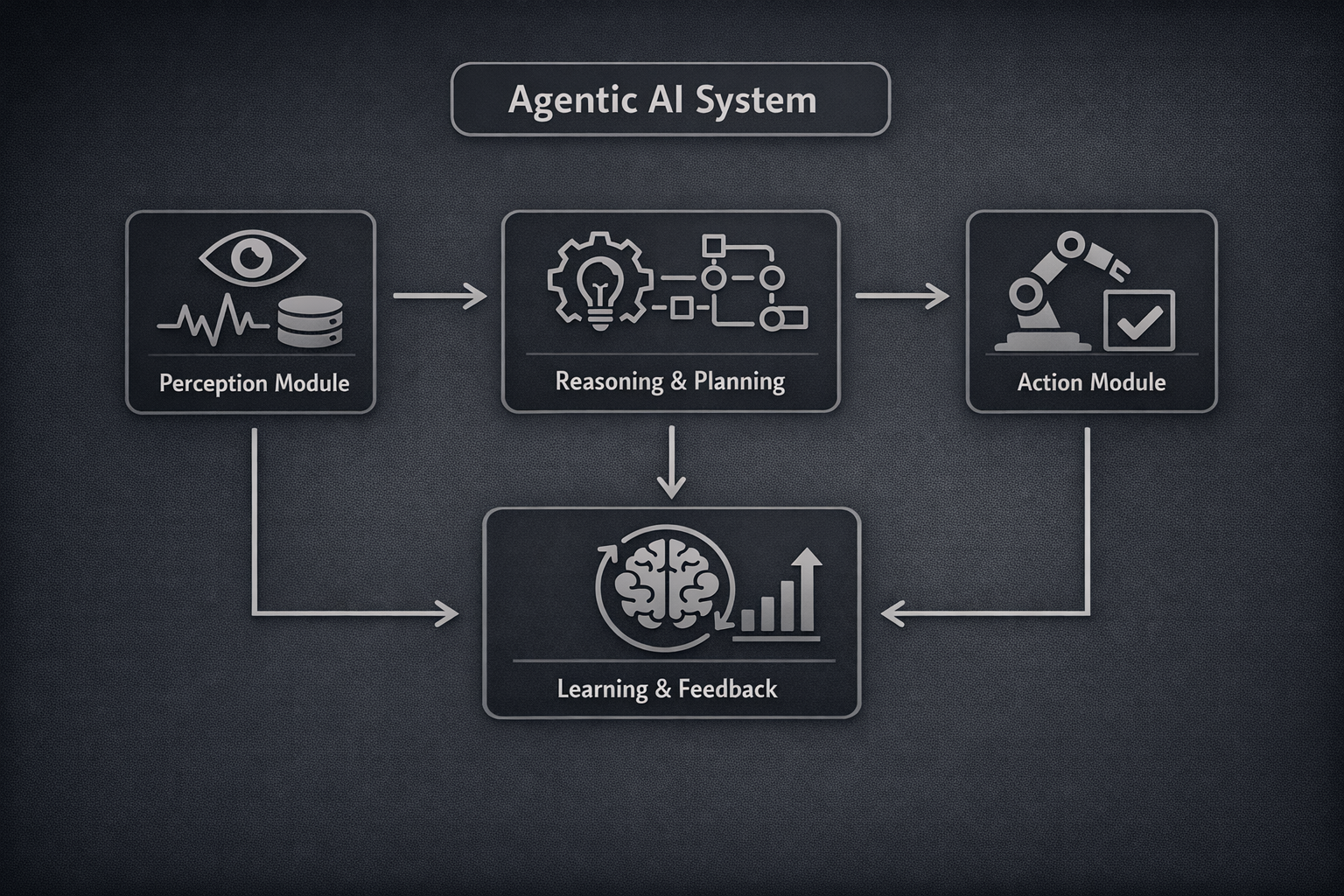
![agentic AI system diagram showing how the components flow together]()
Applied Agentic AI & Reasoning Systems
Designing structured LLM-based systems capable of decision-making, tool use, and environment-aware reasoning.
-
![Environment-Aware Prediction system components and their flow]()
Environment-Aware Prediction Systems
Modeling how environmental conditions and sensor quality impact system performance, enabling adaptive and resilient decision-making while fine-tuning machine learning models.
-
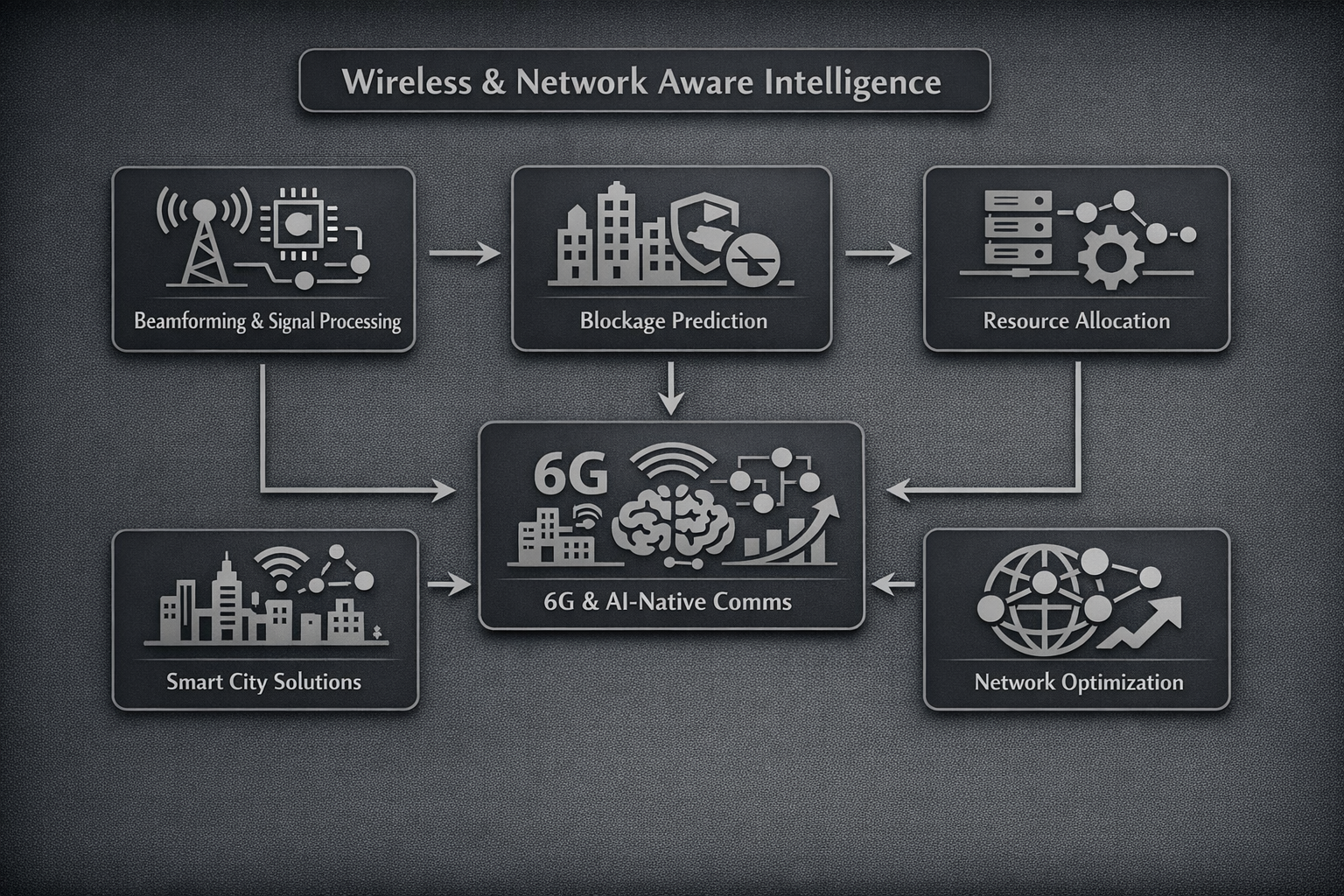
![Wireless network intelligence diagram showcasing how AI-driven methods interact with each other]()
Wireless & Network-Aware Intelligence
Developing AI-driven methods for beamforming, blockage prediction, resource allocation, smart cities, and 6G AI-native communications in next-generation wireless systems.
-
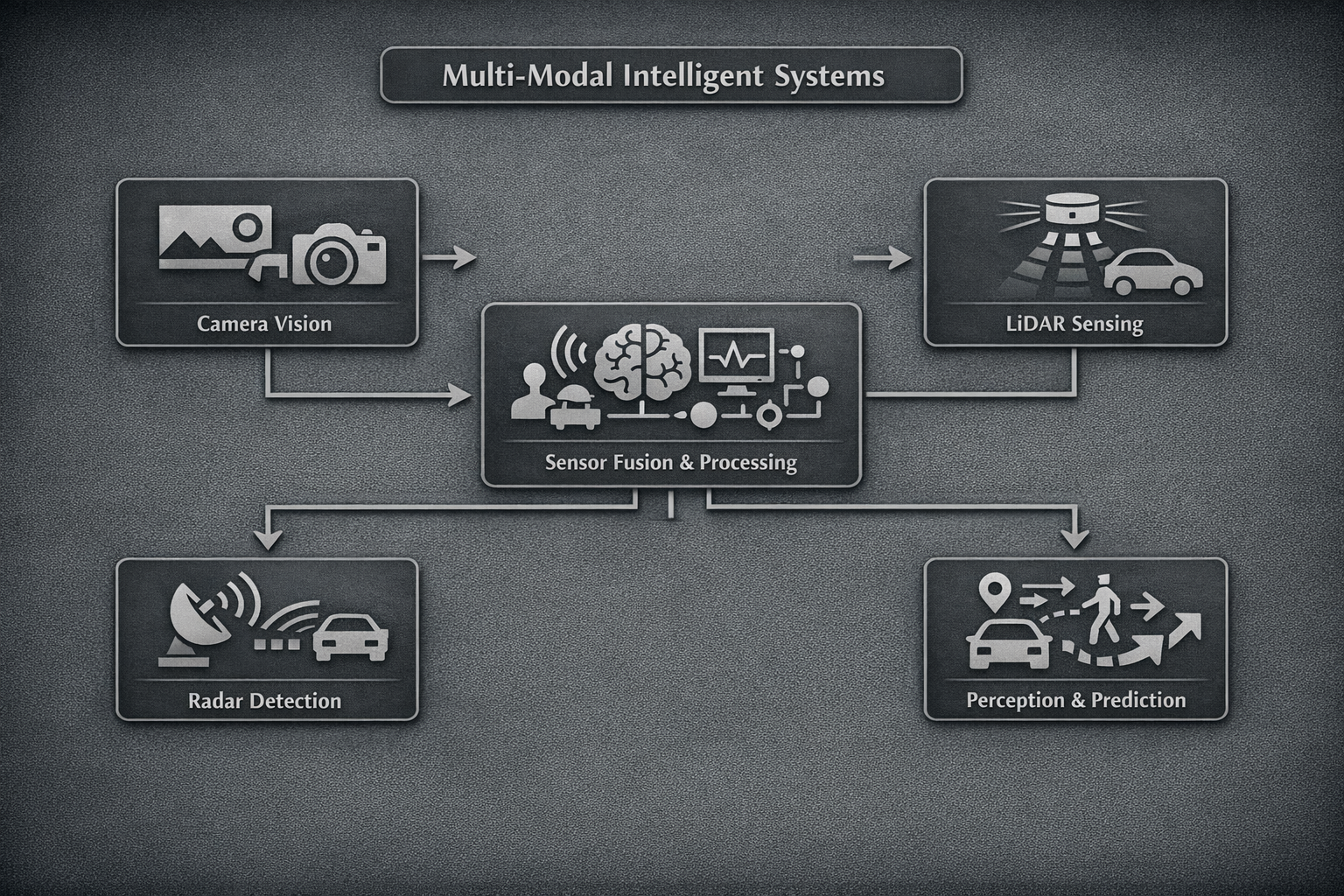
![Multi-modal sensors in various settings and their applications.]()
Multi-Modal Intelligent Systems
Designing systems that integrate multiple sensing modalities, including cameras, LiDAR, and radar, for robust perception and prediction in dynamic environments.

Recent Publications
-
Providers of Relief in Distress: RAG-Based LLMs as Situation and Intent-Aware Assistants
LLooMi is an open‑source, retrieval‑augmented conversational agent designed to provide trustworthy, emotionally aware support in challenging situations such as mental health crises, housing or food insecurity, medical concerns, and immigration issues. Using large language models with structured prompting, LLooMi interprets user needs—even when questions are vague or emotionally charged—and grounds its responses in a curated knowledge base while preserving user privacy. Its intent‑aware design adapts tone and detail based on the user’s state, offering fast, directive guidance during urgent scenarios or more supportive dialogue when reassurance is needed. With strong performance in correctness, relevance, clarity, and trust, LLooMi demonstrates a promising path toward scalable, human‑centered digital support tools for mental health and crisis care.
Citation: Nazar AM, Norman B, Northway H, Toutoungi A, Zatkalik E, Carlson G, Sabado E, Shawa H, Selim MY. Providers of relief in distress: RAG-based LLMs as situation and intent-aware assistants. Front Artif Intell. 2026 Mar 2;9:1712596. doi: 10.3389/frai.2026.1712596. PMID: 41847083; PMCID: PMC12990127.
-
ENWAR 2.0: An Agentic Multimodal Wireless LLM Framework With Reasoning, Situation-Aware Explainability and Beam Tracking
The second iteration of our ENWAR series introduces Enwar 2.0, an agentic AI framework designed for adaptive, explainable wireless network management. Enwar 2.0 combines chain‑of‑thought reasoning with adaptive retrieval‑augmented generation to make informed decisions in dynamic environments. It features two specialized agents—a TransFusion-based beam prediction agent and an environment perception agent—that fuse time-synchronized multi‑modal data such as camera, LiDAR, radar, and GPS data. This enables real-time beam tracking, situation-aware reasoning, and clear justifications for decisions. Compared to the first ENWAR model, Enwar 2.0 offers stronger reasoning, more relevant context retrieval, and significantly higher accuracy. It achieves state-of-the-art performance across correctness, faithfulness, and relevancy while reducing processing time and improving adaptability, marking a major step forward in intelligent and resilient wireless communication systems.
Citation: A. M. Nazar, A. Celik, M. Y. Selim, A. Abdallah, D. Qiao and A. M. Eltawil, "ENWAR 2.0: An Agentic Multimodal Wireless LLM Framework With Reasoning, Situation-Aware Explainability and Beam Tracking," in IEEE Transactions on Mobile Computing, vol. 25, no. 4, pp. 5234-5252, April 2026, doi: 10.1109/TMC.2025.3629736.
-
ENWAR: A RAG-Empowered Multi-Modal LLM Framework for Wireless Environment Perception
ENvironment aWAR (ENWAR) Multi-Modal LLM Framework is a new multi‑modal, environment‑aware AI framework designed to improve how large language models understand and interpret complex wireless environments. By combining camera, LiDAR, radar, and GPS data with a retrieval‑augmented generation (RAG) approach, Enwar provides richer situational awareness than general‑purpose LLMs. Tested on the DeepSense6G dataset and compared with leading models like Mistral and LLaMA, Enwar delivers more accurate spatial insights by identifying positions, obstacles, and line‑of‑sight conditions. It achieves strong performance across relevancy, recall, correctness, and faithfulness, showing its effectiveness in making wireless systems more interpretable, adaptive, and reliable.
Citation: A. M. Nazar, A. Celik, M. Y. Selim, A. Abdallah, D. Qiao and A. M. Eltawil, "ENWAR: A RAG-Empowered Multi-Modal LLM Framework for Wireless Environment Perception," in IEEE Communications Magazine, doi: 10.1109/MCOM.001.2500261.
Link: https://ieeexplore.ieee.org/abstract/document/11368665
-
Multi-Modal Sensor Fusion for Proactive Blockage Prediction in mmWave Vehicular Networks
This work introduces a proactive blockage prediction system for millimeter‑wave vehicular communication using multi‑modal sensing. By combining camera, GPS, LiDAR, and radar inputs, the framework predicts blockages before they occur, enabling more reliable I2V connectivity. Each sensor stream is processed with its own deep learning model, and their outputs are fused using a softmax‑weighted ensemble for improved accuracy. Experiments show strong performance up to 1.5 seconds ahead, with the camera‑only model achieving a 97.1% F1‑score and fast inference, while a camera+radar setup slightly improves accuracy. These results highlight how multi‑modal fusion can enhance proactive wireless communication in dynamic environments.
Citation: A. M. Nazar, A. Celik, M. Y. Selim, A. Abdallah, D. Qiao, and A. M. Eltawil, “Multi-modal sensor fusion for proactive blockage prediction in mmWave vehicular networks,” 2025, arXiv:2507.15769.
-
Encoders, Roll Out! A Digital-Twin Enabled Multi-Modal Sensor Transfusion for Proactive I2V Beam Prediction
This work presents a TransFusion‑based Digital Twin framework for proactive beam prediction in millimeter‑wave infrastructure‑to‑vehicle networks. By synchronizing camera, LiDAR, radar, and GPS data, the Digital Twin maintains a virtual replica of the real environment, allowing beam choices to be evaluated before they are applied. The TransFusion architecture combines modality‑specific encoders, temporal modeling, and transformer refinement to capture long‑range spatial and temporal patterns. Tested on real multi‑sensor data, the system significantly improves beam selection accuracy, with the camera‑GPS‑LiDAR setup reaching 90% Top‑3 accuracy and very low power loss. These results highlight the value of multi‑modal fusion and Digital Twin intelligence for achieving fast, reliable, and efficient wireless communication in dynamic urban settings.
Citation: Coming soon.
Link: Coming soon.
-
Situational Perception in Distracted Driving: An Agentic Multi-Modal LLM Framework
This work introduces an LLM‑driven framework for improving driver safety by delivering real‑time, context‑aware alerts once distraction is detected. The system combines camera and GPS inputs with specialized agentic tools that assess objects, speed limits, traffic conditions, and weather, producing clear and concise verbal interventions. Designed to avoid overwhelming the driver, it fuses information efficiently and responds quickly. The framework achieves strong performance, including 85.7% correctness and low response latency, outperforming traditional machine‑learning approaches. Overall, it demonstrates the potential of multi‑modal, LLM‑based reasoning to support safer decision‑making in critical driving scenarios.
Citation: Nazar AM, Selim MY, Gaffar A and Qiao D (2025) Situational perception in distracted driving: an agentic multi-modal LLM framework. Front. Artif. Intell. 8:1669937. doi: 10.3389/frai.2025.1669937
Link: https://www.frontiersin.org/journals/artificial-intelligence/articles/10.3389/frai.2025.1669937/full
-
NextG-GPT: Leveraging GenAI for Advancing Wireless Networks and Communication Research
NextG‑GPT is an AI‑driven framework designed to enhance wireless network research by combining large language models with retrieval‑augmented generation. Using state‑of‑the‑art LLMs and a domain‑focused knowledge base, it delivers context‑aware, real‑time support for complex wireless questions. Evaluations across models such as Mistral, Mixtral, and LLaMa3 show strong gains in accuracy, relevance, and correctness, with LLaMa3.1‑70B achieving notably high performance. By incorporating datasets like ORAN‑13K‑Bench, TeleQnA, TSpecLLM, and Spec5G, NextG‑GPT provides precise, reliable insights tailored to next‑generation networks. This framework sets a new benchmark for AI‑assisted research and helps pave the way for more intelligent and efficient wireless communication systems.
Citation: A. M. Nazar, M. Y. Selim, D. Qiao and H. Zhang, "NextG-GPT: Leveraging GenAI for Advancing Wireless Networks and Communication Research," 2025 34th International Conference on Computer Communications and Networks (ICCCN), Tokyo, Japan, 2025, pp. 1-9, doi: 10.1109/ICCCN65249.2025.11133874.
Link: https://ieeexplore.ieee.org/abstract/document/11133874